Why AI-Era Systems Need Tokenization Before Encryption
Securelytix Team
Product & Security
7 May 2026
By Securelytix Engineering | Technical Deep-Dive | Architecture · AI Security · Privacy Engineering
The Problem Is Data Flow, Not Data Storage
Most engineering teams already have the fundamentals in place: TLS for data in transit, AES-256 encryption at rest, IAM policies, key management, and regular backup routines. And yet, incidents continue.(Read More - Tokenization Vs Encryption)
The reason is not a gap in storage protection. The gap is runtime exposure - what happens to sensitive data after it is decrypted for legitimate use.
In a traditional stack, sensitive data moved between a small, well-understood set of surfaces: an API, a database, an internal service. You could reason about the exposure footprint and guard it.
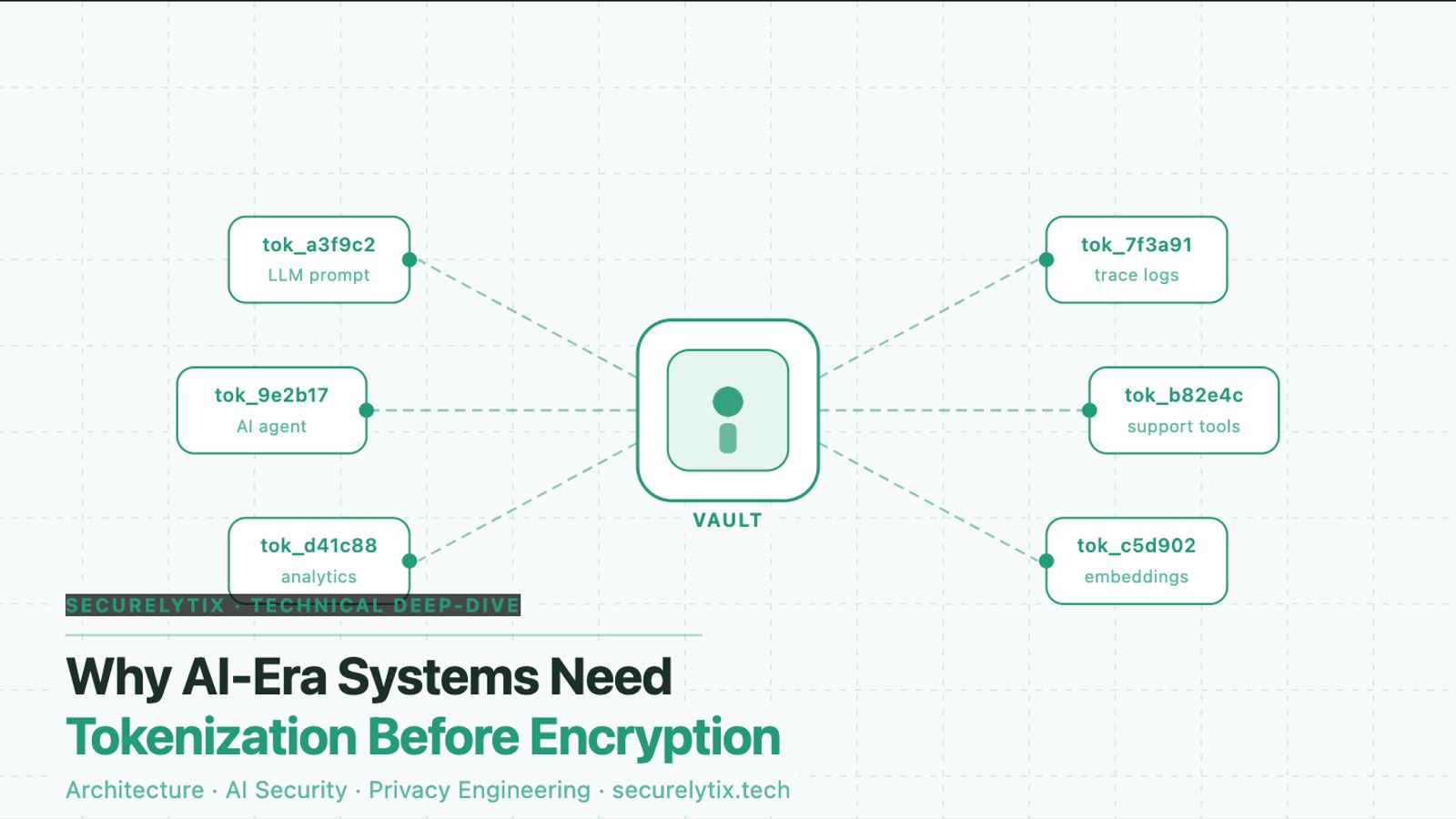
In an AI-connected stack, the same data now passes through:
- LLM prompts and system contexts
- Agentic workflows pulling from multiple upstream systems
- Vector embeddings and retrieval pipelines
- Observability, tracing, and debug pipelines
- Analytics and BI connectors
- Support and QA copilots
- Third-party integrations and webhook consumers
Each of these surfaces can receive, log, cache, or re-transmit sensitive data - usually without anyone having made a deliberate decision to expose it there.
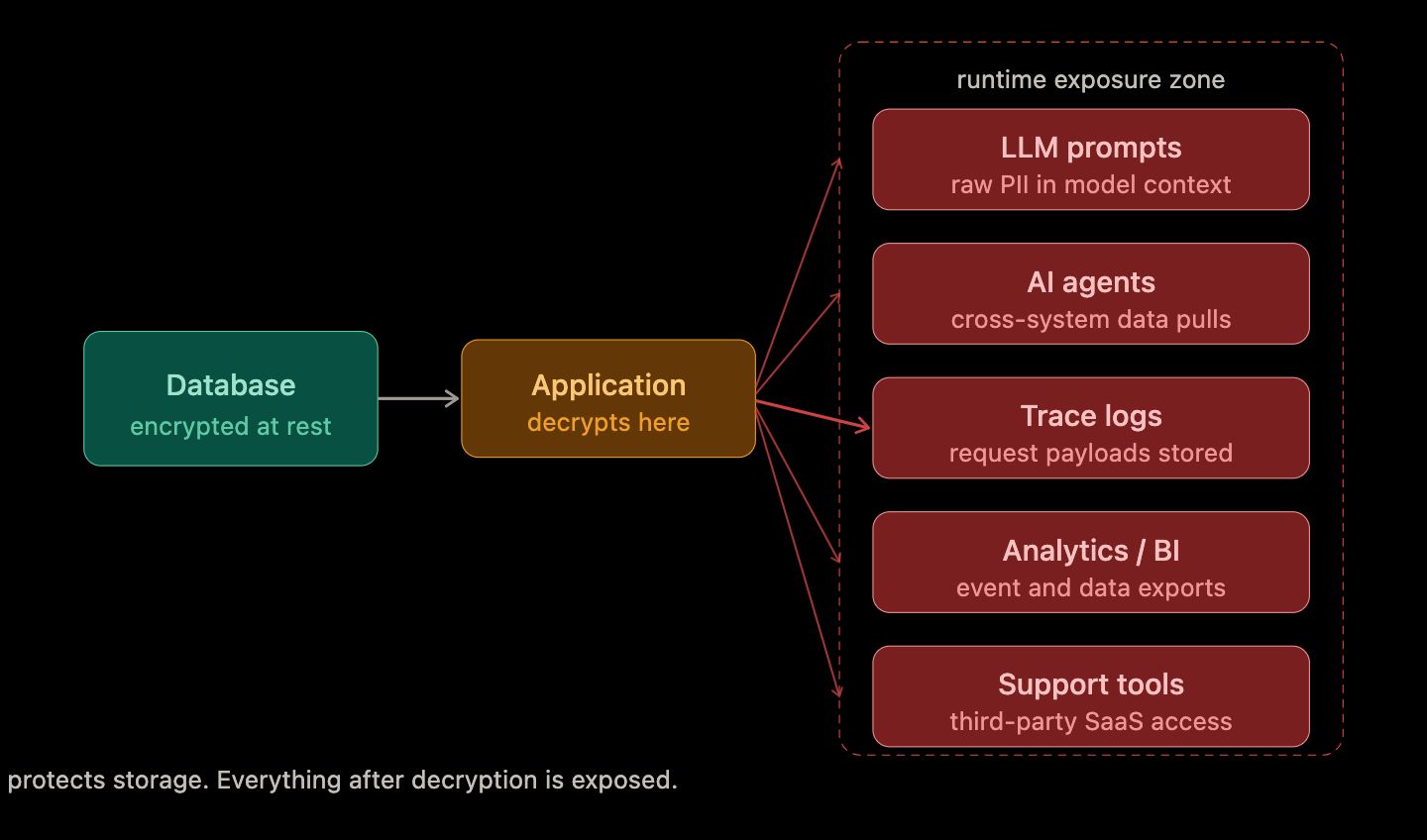
Encryption protects what is stored. It says nothing about what happens once the application decrypts data and it starts moving. The vault is well protected. But data is unguarded everywhere it flows after the vault opens.
This is the exposure problem that tokenization-first architecture is designed to solve.
What Tokenization-First Means in Practice
Tokenization-first is not a single security control. It is an architectural posture - a deliberate decision about when sensitive data is allowed to exist in its raw form, and for how long.
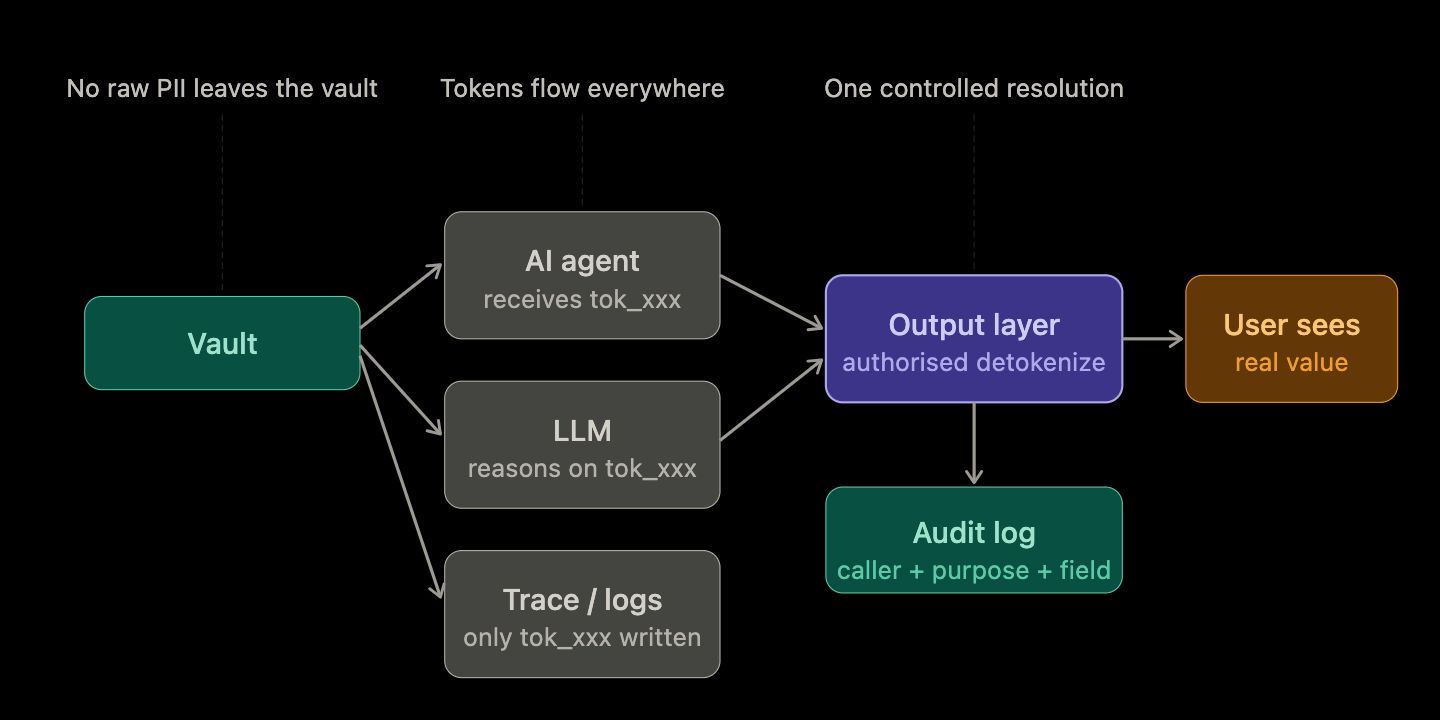
The governing principle: replace sensitive values with opaque tokens as early as possible in the data lifecycle. Store real values in a controlled mapping layer. Let all other systems - analytics, logs, agents, prompts, third-party APIs - work with tokens only. Allow raw value retrieval only for explicit, approved, auditable operations.
In a tokenization-first system, a customer's Aadhaar number, phone number, or PAN card is assigned a token like tok_cust_7f3a91c2d4e5 at the point of ingestion. That token flows through every downstream system. The raw value lives only inside the vault, resolved on demand for authorised callers with a declared purpose.
Most application logic - order processing, recommendations, analytics, support tooling - does not need the raw value. It functions perfectly on the token. This is the operational insight that makes tokenization-first practical: you are not blocking workflows. You are making raw data unnecessary for the majority of them.
SECURELYTIX IMPLEMENTATION NOTE Securelytix tokenizes at the field level, not the record level. You can protect an Aadhaar column without touching the rest of a customer schema. Tokenization happens at the API boundary or ingestion layer, before data lands in any downstream system. Detokenization is purpose-bound: the same field can be accessible for loan underwriting and blocked for marketing profiling - defined by policy, not by code changes.
Why the AI Era Changes the Calculus Entirely
Earlier generations of data architecture had a manageable number of surfaces where sensitive data could appear. AI-connected systems have fundamentally different failure modes.
Failure pattern 1: Prompts that include raw PII
An agent or copilot calls a CRM to build context for a customer query. The CRM returns the full customer record - name, phone, email, Aadhaar-linked ID, transaction history - and that data goes directly into the LLM prompt. The model processes it, logs it for tracing, and may include fragments in its response. The sensitive data is now in the model context, the trace log, and potentially an output that reaches unintended recipients.
With tokenization-first, the CRM returns tokenized representations. The agent has enough context to reason about the customer without ever handling raw PII. Only the final, policy-approved rendering step resolves tokens to real values for the user who is authorised to see them.
Failure pattern 2: Agents combining data across systems
A modern AI agent might pull records from a CRM, cross-reference a payment system, and look up a profile in a health database - assembling a detailed composite of a person that no single source system was designed to expose. If each source returns raw values, the agent creates a data concentration that is far more sensitive than any individual source.
Tokenized outputs from each source prevent this aggregation. The agent works with tokens. No composite of real PII is assembled at runtime.
Failure pattern 3: Telemetry that captures what it should not
Distributed tracing and observability pipelines capture request and response payloads to assist debugging. In AI systems, those payloads often include prompt contents - and prompt contents often include whatever data was retrieved to build context. One misconfigured
tracing pipeline can result in PII sitting in a logging service indefinitely, accessible to anyone with observability access.
Redacting PII from telemetry pipelines after the fact is brittle. Regex-based scrubbers miss new field names and structured formats. Tokenization-first means there is nothing to scrub: the telemetry pipeline sees tokens from the start, because that is all the application ever handled.
ENGINEERING TRADEOFF The strongest objection to tokenization-first is operational overhead: every service that needs real values must make a vault call. In practice, this adds 1–5ms per detokenization. High-throughput paths are handled with batch token resolution and short-lived caching. The more important tradeoff is cognitive: engineers must reason about token scope explicitly, rather than assuming ambient data access. This is overhead - but it is exactly the kind of overhead that makes exposure footprint legible.
"Why Not Just Use Encryption?"
You absolutely should. Encryption is mandatory. The question is not encryption versus tokenization - it is understanding what each one actually protects.
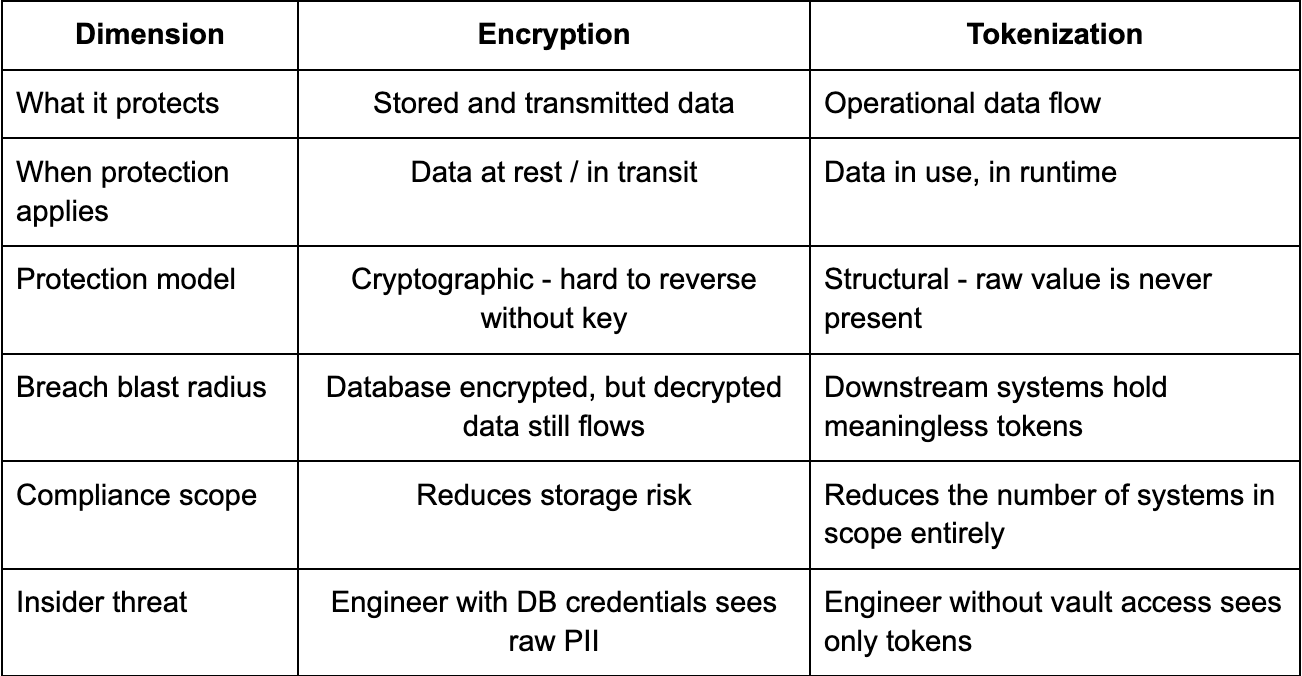
Encryption protects data while it is locked. Tokenization reduces how often the lock is opened and who can walk through the door when it is.
The best practice is not one or the other. The best practice is tokenization plus encryption: tokenized values stored in the application layer, raw values encrypted at rest inside the vault.
The Blast Radius Difference
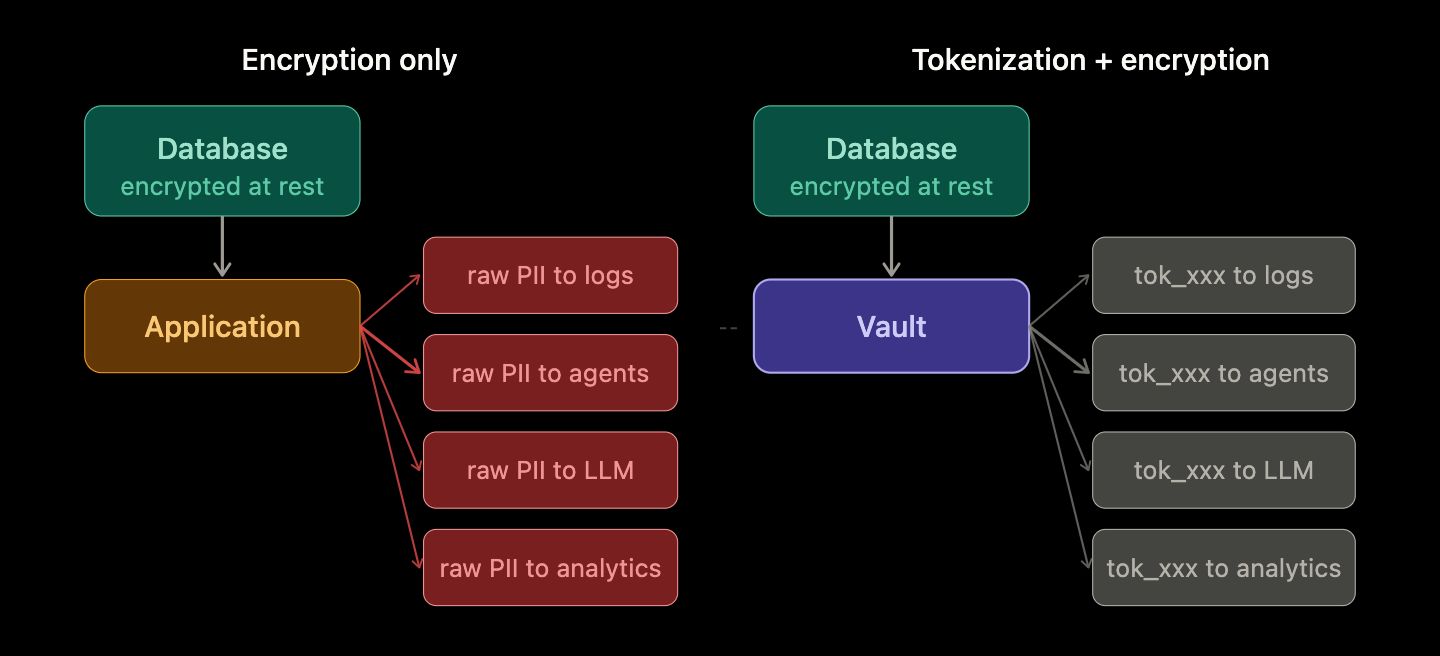
The most important property of tokenization-first is not prevention - it is containment.
An attacker who successfully exfiltrates your application database in a tokenized system gets a large table of tokens: tok_cust_4a8b2f, tok_cust_9d3e7c, tok_phone_1a2b3c. These resolve to nothing without vault access. The haul is computationally worthless.
An attacker who exfiltrates the same database in a raw-PII system gets names, phone numbers, Aadhaar-linked identifiers, PAN numbers, and health records - immediately usable, immediately harmful, immediately the basis of a regulatory disclosure event.
This changes the character of a breach entirely. The first scenario is a recoverable security incident. The second is a company-defining crisis.
For enterprises handling Aadhaar-linked identifiers, UPI handles, and financial records at scale, that difference is not an engineering preference. It is an obligation to the customers who trusted you with their data.
THE BLAST RADIUS INSIGHT A breach of a tokenized application database is categorically different from a breach of a raw-PII database. What the attacker exfiltrates from your orders table, your analytics store, or your support platform is meaningless without vault access - because the sensitive data never left the vault in the first place.
A Practical Rollout Plan Teams Can Actually Execute
Introducing tokenization-first into an existing platform is a multi-quarter engineering project. The goal of phased rollout is to achieve measurable risk reduction at each stage without blocking product velocity.
Phase 1: Discover
Identify where sensitive fields currently live. Map where they flow - APIs, logs, BI exports, support tickets, agent inputs. Most teams discover that sensitive values appear in far more places than expected. The audit itself is valuable.
Phase 2: Prioritise
Start with highest-risk fields: Aadhaar numbers, PAN cards, phone numbers, UPI handles, health identifiers, and payment card numbers. Start with highest-churn paths: support tools, analytics pipelines, and AI-facing surfaces. These are where the exposure footprint is largest and growing fastest.
Phase 3: Tokenize at ingress
Tokenize at the API boundary or ingestion layer, before sensitive values land in any downstream system. Use dual-read mode to tokenize new writes while existing read paths remain operational. You do not need a big-bang migration to begin reducing risk.
Phase 4: Enforce access
Define strict detokenization policies by service identity, operation type, and declared purpose. Build audit trails for every vault call - caller identity, declared purpose, field accessed, outcome. Treat the audit log as the mechanism by which trust is verified, not as optional instrumentation.
Phase 5: Harden AI surfaces
Block raw sensitive fields from reaching LLM prompts and agent tool inputs. Ensure agentic workflows receive tokenized payloads from every connected system. Redact or tokenize sensitive values in telemetry and debug outputs before they reach observability pipelines.
ON MIGRATION The pragmatic path is phased: introduce tokenization alongside existing direct database access (dual-read mode), tokenizing new writes while maintaining read compatibility. Progressively migrate read paths service by service. For a mid-sized system, expect four to eight months to fully migrate your highest-sensitivity data paths.
What Happens at the AI Boundary
The most important configuration decision in a tokenized AI system is what data the model surface is allowed to receive.
A practical rule: no raw sensitive field should enter an LLM prompt or agent tool call. Tokens are semantically opaque to the model - it cannot infer a phone number from a token - but they are operationally useful. The model can reference a customer, look up related records, or route a request based on token identifiers without ever handling real PII.
When the workflow requires a real value - displaying a phone number to an authorised support agent, rendering a name in a confirmed notification - that detokenization happens at the final output layer, under policy control, and is fully logged.
The model has done its reasoning. The support agent has the context she needs. No raw sensitive data passed through the model, the agent framework, or the telemetry pipeline.
SECURELYTIX IMPLEMENTATION NOTE Securelytix enforces this at the policy layer, not the application layer. You define which services can call the vault, for which fields, for which declared purposes. The application does not implement access control logic - the vault enforces it consistently across every caller. This means your AI surfaces, your analytics pipelines, and your support tools all operate under the same policy framework, with a single audit trail.
Compliance Reality: Strong Foundation, Not a Magic Checkbox
Tokenization-first aligns with the data minimisation and privacy-by-design principles that underpin GDPR, India's Digital Personal Data Protection Act (DPDP), HIPAA, PCI-DSS, and related frameworks. It materially reduces the number of systems in compliance scope, simplifies audit evidence, and makes data subject rights - access, correction, deletion - technically tractable.(Read More-Privacy by Design Architecture)
But one important truth: no architecture alone guarantees automatic legal compliance in every jurisdiction. Legal basis for processing, retention rules, data residency requirements, consent management, and user rights workflows still require deliberate legal and engineering attention.
What tokenization-first does is make compliance engineering cleaner, faster, and more scalable. When regulators ask which systems processed a particular customer's data, your answer can be: the vault processed it; everything else processed a token.

Final Takeaway
In the AI era, a secure architecture is not defined only by strong encryption. It is defined by how rarely raw sensitive data is allowed to move.
Encryption protects stored value. Tokenization protects operational flow. For teams building AI-connected products, these are not alternatives - they are complementary layers that address different parts of the exposure problem.
The shift from traditional application stacks to AI-connected stacks has fundamentally expanded the number of surfaces where sensitive data can appear. Agentic workflows, LLM prompts, observability pipelines, and third-party integrations are all new exposure vectors that encryption alone does not address.
Tokenization-first closes that gap: most systems receive tokens, operate on tokens, and log tokens. The raw value lives in the vault, accessed only when necessary, by authorised callers, for declared purposes, with every access recorded.
For enterprises managing Aadhaar-linked identifiers, UPI handles, and financial records at scale, that posture is quickly moving from best practice to baseline expectation.
How Securelytix Approaches This
Building a tokenization-first architecture from scratch requires vault infrastructure, token schema design, access policy management, audit pipelines, and the slow work of migrating existing services. Most enterprise teams find the architecture clear in principle but difficult to operationalise without a dedicated platform underneath it.
Securelytix is India's first indigenous privacy vault, built specifically for this architecture. A few things worth knowing about how it works in practice:
Field-level tokenization. PII fields are tokenized at the point of ingestion - individual columns, not entire tables. You can protect Aadhaar numbers in one table without touching the rest of the schema.
Policy-based access control. Access policies are defined by service identity, operation type, and declared purpose. The same data field can be accessible for one business reason and blocked for another, without code changes.
On-premise and cloud deployments. For enterprises with data residency requirements under DPDP or RBI guidance, the vault runs entirely within your own infrastructure. No customer data transits Securelytix systems.
Incremental migration path. Dual-read mode lets you tokenize new writes while existing read paths continue working. Most teams begin with their highest-sensitivity fields and highest-risk AI surfaces.
Audit log out of the box. Every detokenization event is logged with caller identity, declared purpose, field accessed, and outcome. The log is structured, tamper-evident, and exportable for compliance workflows.
The architecture described in this post is exactly what Securelytix implements - not as a managed service that handles your data, but as infrastructure that runs inside your environment.
If you are evaluating how to approach tokenization-first for your organisation: securelytix.tech
Frequently Asked Questions
Does tokenization add too much latency?
Vault calls add 1–5ms per detokenization under normal conditions. For most enterprise workflows, this is imperceptible. High-throughput paths are handled with batch token resolution and short-lived caching. Securelytix supports batch token issuance natively - one vault call covers a bounded set of records for a declared job context.
Does tokenization break our analytics pipelines?
Not if implemented correctly. Tokens are consistent references: the same sensitive value always produces the same token. This means standard analytical operations - joins, counts, group-bys, cohort analysis - work on tokenized data exactly as they would on raw data. Only operations that require the actual value (displaying a name, sending a notification) require detokenization, and those are handled at the output layer.
Why does this matter specifically for Indian enterprises?
Indian enterprises handle some of the world's most sensitive citizen-linked identifiers: Aadhaar numbers, PAN cards, UPI handles, health records under the ABDM framework, and financial data under RBI guidance. A successful breach of a raw-PII database in this context means the real identifiers of millions of people are immediately exposed. A breach of a tokenized system means an attacker got computationally worthless strings. Securelytix is India's first indigenous privacy vault, built for this data landscape and deployable on-premise for data sovereignty requirements.
What does Securelytix actually do in this architecture?
Securelytix implements the vault layer: field-level tokenization at ingestion, policy-based detokenization for approved callers with declared purposes, tamper-evident audit logs for every vault operation, and on-premise deployment for enterprises with data residency requirements. Engineers integrate via API or SDK. The vault enforces access control consistently across every caller - application services, AI agents, analytics pipelines, and support tools all operate under the same policy framework, with a single audit trail.
Ready to Secure Sensitive Data?
Explore how Securelytix helps teams protect sensitive data, enforce privacy controls, and build Secure AI deployment.