Why Masking PII at the Frontend Is Not Enough: The Backend Exposure Problem
Securelytix Team
Product & Security
20 May 2026
The Comfortable Lie That Frontend Masking Tells
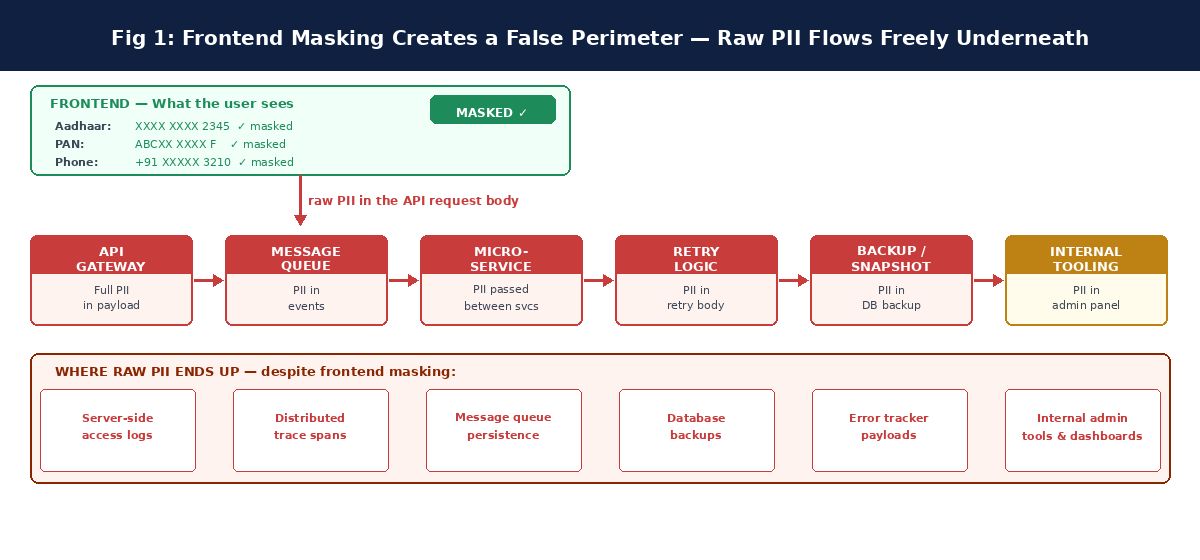
There is a moment in most compliance conversations about PII where someone points at the UI and says: we have that covered. The Aadhaar number shows as XXXX XXXX 2345 in the support interface. The PAN card is ABCXX XXXX F in the customer dashboard. The phone number is +91 XXXXX 3210 in the CRM. It looks protected. The screen looks clean. The audit trail shows masked values wherever a human is looking at the data.
This is one of the most expensive misunderstandings in data privacy architecture. Frontend masking is a display control, not a data control. It changes what a human sees on a screen. It does not change what the system stores, transmits, queues, logs, backs up, or retries. The raw Aadhaar number that appears as XXXX XXXX 2345 on a support agent's screen is, simultaneously, travelling in plaintext through your API layer, sitting unencrypted in a message queue, being logged by your distributed tracing infrastructure, copied into a database backup that lives outside your primary access controls, and potentially visible in an internal admin tool used by your engineering team.
This is the backend exposure problem. And unlike the frontend risk - which is visible, discussed, and partially mitigated in most organisations - it is almost entirely invisible. The data is leaking through systems that were never part of the original data privacy conversation, through pathways that no compliance checklist was designed to catch, through tools that your engineering team installed to make operations easier without any awareness that they were creating a PII exposure surface in the process.
Understanding what is sensitive data exposure in a modern microservices backend means following the data past the display layer and mapping every system it touches before it reaches storage - and every system that touches it after. This post is that map.
What Frontend Masking Actually Does - and Does Not Do
To understand why frontend masking is insufficient, you need to be clear about what it actually is architecturally. Frontend masking is a rendering decision. The application receives a value, decides how to display it, and shows only part of it to the human on the screen. The full value was already retrieved. It already travelled over the network. It may already have been logged. The masking happens at the very last step - the moment of display - and nowhere else.
In some implementations, the masking happens slightly earlier: the API itself returns a pre-masked value, so XXXX XXXX 2345 is what the frontend receives rather than 4567 8901 2345. This is better. But it only moves the problem one step upstream. The API endpoint returned a masked value. The service that called that API to retrieve the data still received the full value. The database query that ran to fetch it still touched the full value. The trace that was recorded for that database query still contains the full value.
Masking is a last-mile control. It protects the final display. It does nothing for the journey. And in a modern microservices backend, the journey involves ten to fifteen systems before data reaches the display layer, and at least half of them create durable records of what they handled.
THE CORE DISTINCTION
Data masking changes what humans see. Data tokenization changes what systems store and transmit.
A masked Aadhaar number is still a real Aadhaar number - it is just displayed with asterisks. A tokenized Aadhaar number is a cryptographically secure surrogate that cannot be reversed without the vault. One protects the screen. The other protects the data. Only one of them satisfies the technical requirements of DPDP and GDPR for pseudonymisation.
The Eight Backend Surfaces Where PII Leaks
In a typical fintech or enterprise backend, there are eight distinct surfaces where PII can accumulate in systems that are not part of the production data store - and therefore not subject to the access controls and tokenization that protect the primary database. None of them are reached by frontend masking. All of them represent real compliance exposure under DPDP and GDPR.

APIs: The First System That Sees Raw PII
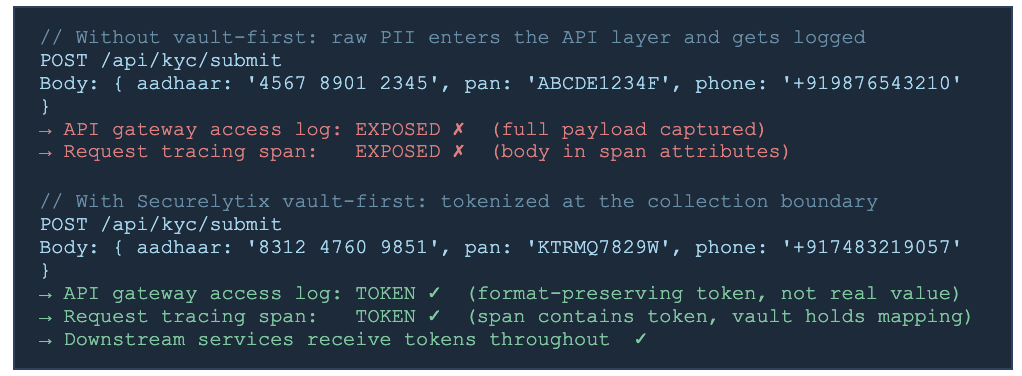
When a user submits a KYC form with their Aadhaar number, the first system that receives it is not a database. It is an API gateway. And API gateways, by default, log what they receive. Access logs, request tracing, rate limiting infrastructure, API management platforms - all of them create records of what passed through them, and most of those records contain the full request body.
The masking that appears on the frontend has not happened yet at this point. Even if the API itself is designed to return masked values, the incoming request - the one containing the raw Aadhaar number - has already been logged. The outgoing response - containing the masked value - appears in the same log alongside the incoming request that contained the real one.
This is one of the most common sources of PII in infrastructure logs, and it is the most direct answer to the question of how to redact PII from logs at the API layer. The answer is not to mask the display. It is to intercept and tokenize the value before it enters the API processing pipeline - so that the value the API gateway sees, logs, and forwards is a token, not a real Aadhaar number.
What proper API-layer protection looks like
Message Queues: Where PII Waits to Be Exfiltrated
Event-driven architectures are the dominant pattern in modern microservices systems. A user submits a loan application. An event is published to Kafka. A dozen consumers - the KYC service, the fraud scorer, the document processor, the notification system, the audit logger - each receive a copy of that event and process it independently. This is a well-designed system. It is also, if not built with PII tokenization in mind, a system that has just distributed the applicant's full Aadhaar number, PAN card, and phone number to twelve different services simultaneously.
The problem is not just the distribution. It is the persistence. Kafka topics have retention windows - often 24 hours for operational topics, but sometimes days or weeks for compliance or replay purposes. During that retention window, every message in the topic is readable by any consumer with access to the Kafka cluster. If a service is compromised, or if a developer runs a consumer on their local machine against the production Kafka cluster to debug an issue, every message in the retention window is accessible.
How to protect PII in Kafka streams is one of the highest-priority data engineering challenges for any organisation running event-driven pipelines with PII. The solution is the same as at the API layer: tokenize before publication, not after. The event should be published with format-preserving tokens in sensitive fields. The real values stay in the vault. Any consumer that needs a real value for a specific purpose calls the vault with the appropriate purpose declaration.
THE KAFKA RETENTION WINDOW PROBLEM
A Kafka topic with a 7-day retention window and 10,000 loan applications per day contains 70,000 full customer records at any given time - all readable by anyone with consumer access to the cluster.
This is not a hypothetical risk. It is a feature of how Kafka is designed. The only way to ensure that retention window does not hold raw PII is to ensure that the messages published to it never contained raw PII in the first place.
Retry Logic: The PII Copy Machine
Retry mechanisms are one of the least-discussed PII leak surfaces in backend systems, and one of the most consequential. When a service call fails - a downstream API is unavailable, a database is temporarily unreachable, a network partition occurs - the standard response is to retry. The request is queued for retry, either in memory, in a database-backed queue, or in a dedicated retry infrastructure like a dead-letter queue.
The retry payload is typically the original request body. The original request body contains the original PII. So every time a service experiences a transient failure handling a PII-containing request, a copy of that PII is written to the retry store. If the failure persists, multiple copies are written - one for each retry attempt. If the request ultimately fails and ends up in a dead-letter queue, the PII sits there indefinitely, often without any of the access controls or retention policies that apply to the primary data store.
This is a sensitive data exposure path that is created entirely by normal, correct retry behaviour. There is no misconfiguration here. The retry logic is working exactly as designed. The problem is that nobody thought to apply the same protection to the retry payload that was applied to the primary data flow.
The fix is architectural: if the primary data flow uses tokenized values, the retry payload also contains tokenized values. There is nothing to protect in the dead-letter queue, because the dead-letter queue holds tokens, not real Aadhaar numbers.
Distributed Tracing and Observability: The Compliance Team's Nightmare
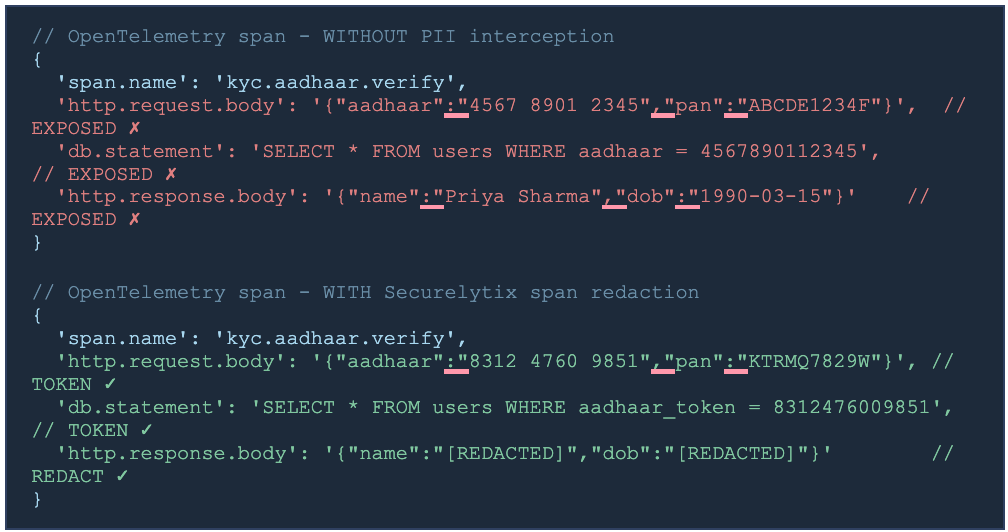
Distributed tracing has become a standard part of production operations for any team running a microservices architecture. OpenTelemetry, Jaeger, Zipkin, Datadog APM - these tools capture the full journey of a request across services, including timing, context, and in many implementations, the actual data that was passed at each hop.
The default configuration for most tracing frameworks captures request and response bodies as span attributes. This means that a trace of a KYC workflow contains the Aadhaar number at the ingestion span, the full customer record at the CRM query span, the PAN number at the fraud scoring span, and the bank account details at the payment span. The complete journey, including every piece of PII that was handled, is recorded in a single trace that is exported to whatever observability platform the team uses.
Most observability platforms are SaaS products - Datadog, New Relic, Grafana Cloud, Honeycomb. They run outside your infrastructure. Sending traces containing raw PII to these platforms is a data transfer to a third-party processor. Under DPDP, this requires a data processor agreement and may constitute a cross-border data transfer depending on where the platform's infrastructure is located.
The practical solution - how to redact PII from logs and traces - requires an interception layer that processes span data before it is exported, replacing sensitive field values with tokens or redacted placeholders. This is not the same as scrubbing logs after the fact. Post-hoc scrubbing is unreliable and misses edge cases. The tokenization needs to happen at the span creation point, before the data leaves your infrastructure.
Database Backups: The Compliance Boundary Nobody Audits
Every production database is backed up. This is non-negotiable infrastructure hygiene. But the compliance posture applied to the production database - field-level encryption, access controls, tokenization, audit trails - does not automatically apply to the backup. A backup is a copy of the data at a point in time, stored in a format optimised for restoration speed, typically in object storage with a completely different access control model from the database itself.
The result is that an organisation can have an extremely well-governed production database with field-level tokenization, granular access control, and a comprehensive audit trail - and simultaneously have eighteen months of unencrypted, untokenized raw PII sitting in an S3 bucket accessible to anyone with the appropriate IAM role in the organisation's AWS account.
How to handle PII in test environments is a related problem. Database backups are frequently used to seed staging and development environments with realistic data. The reasoning is understandable - developers need realistic data to build and test against. The consequence is that production PII ends up in an environment with no production-equivalent controls, accessible to a much broader set of people, and with no audit trail of who accessed what.
Under DPDP, there is no distinction between "production PII" and "staging PII." Personal data is personal data regardless of which environment it lives in. An Aadhaar number in a staging database is subject to the same obligations as an Aadhaar number in production. Most organisations are not operating their staging environments at that standard.
THE BACKUP BLIND SPOT
If your production database holds tokenized values - as it should - your backups should also hold tokenized values. The backup of a vault-first database is a backup of tokens. Restoring from that backup into any environment gives you the tokens, not the real values. The real values remain in the vault.
This is one of the least-discussed benefits of vault-first architecture: it makes your backup and disaster-recovery posture privacy-safe by default, with no additional controls required on the backup storage layer itself.
Internal Tooling: The Masking Exception That Wasn't Supposed to Exist
Every organisation that has been operating for more than a few years has accumulated internal tools. Admin panels built by engineers to make operations easier. Customer lookup interfaces for the support team. Reconciliation dashboards for the finance team. Bulk export tools for the data team. These tools were built quickly, by people solving specific operational problems, and they were almost never built with data privacy in mind.
The typical internal admin tool connects directly to the production database with a service account that has broad read access, because that was the easiest way to get the data it needed. It displays raw field values, because there was no existing masking layer for internal tools to consume. It may have logging of its own, because the developer who built it added logging to debug issues, and never went back to remove the raw PII from those log entries.
Internal tooling is often the longest-lived and least-reviewed part of a technical stack. A tool built in 2018 to help the support team look up customer records may still be in production use, running against the same service account, displaying the same raw values, with no audit trail of how many times it has been used or which records have been accessed. The frontend masking that was implemented in the main application in 2022 was not retrofitted to the internal tool.
This is a significant risk surface under DPDP's requirements around purpose limitation and access logging. Access to personal data must be for a declared purpose, and evidence of that purpose must be maintainable. An internal tool that connects directly to the database with broad credentials satisfies neither requirement.
The Architecture That Actually Fixes This
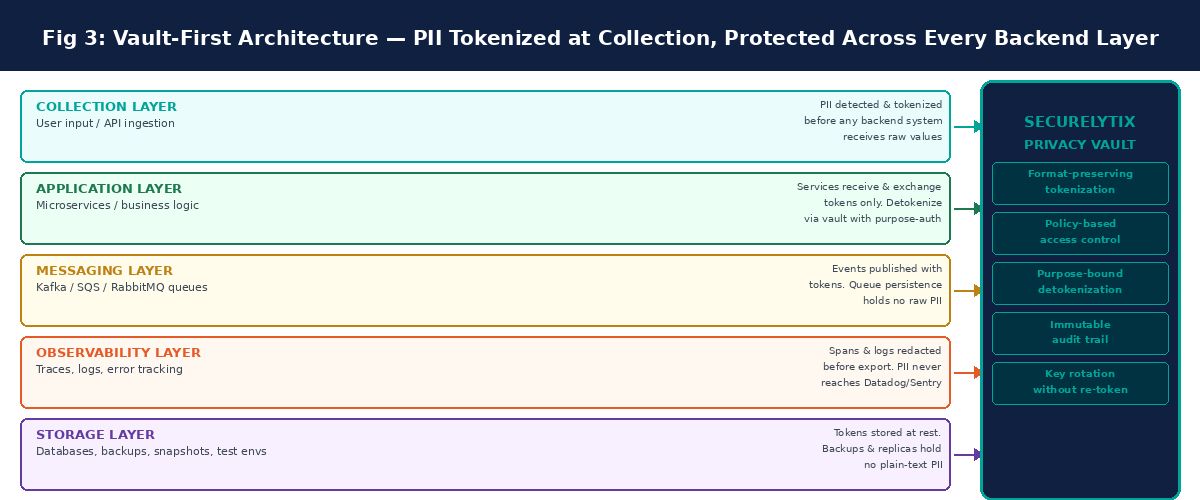
The fix for the backend exposure problem is not a longer list of places to apply masking. Masking is the wrong primitive for backend data protection. The correct primitive is PII tokenization - replacing sensitive values with format-preserving tokens at the earliest possible point in the data flow, so that every system downstream of that point handles tokens rather than real values.
This is the vault-first architecture principle applied comprehensively. What is a privacy vault in this context is precisely the infrastructure that makes this possible: a system that stores the mapping between real values and their tokens, governs who can access the real values under what circumstances, and provides an audit trail of every access event.
When vault-first is implemented correctly, the eight backend leak surfaces described in this post all resolve to the same condition: they hold tokens. The API gateway logs tokens. The Kafka topic contains token-valued events. The retry dead-letter queue holds tokenized request bodies. The distributed trace shows tokenized field values. The database backup is a backup of tokenized data. The internal admin tool displays tokenized fields. None of these systems ever had the real Aadhaar number. There is nothing to protect at any of these surfaces because the real value was never there.
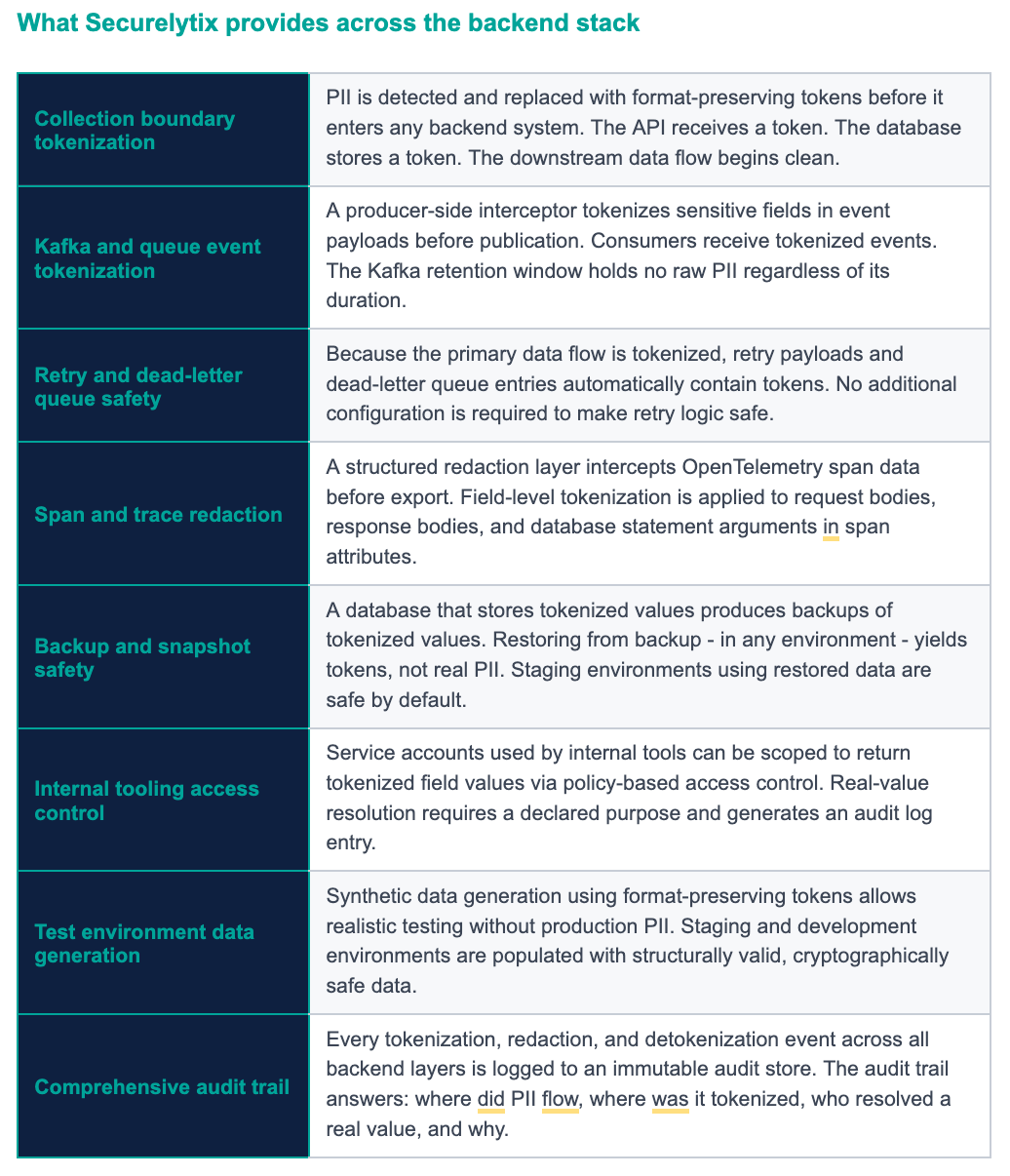
The Regulatory View: DPDP Does Not Distinguish Between Frontend and Backend
India's Digital Personal Data Protection Act - and GDPR, PCI-DSS, and HIPAA before it - does not make any distinction between PII that is visible to a human on a screen and PII that is sitting in a Kafka topic, a database backup, or a distributed trace. Personal data is personal data. The obligation to protect it, to limit access to it, to audit access to it, and to minimise the collection of it applies equally to every system in which it exists.
This has a specific practical implication for organisations that have invested in frontend masking and consider their PII compliance posture to be solid: the investment was in the wrong place. A regulator investigating a data breach does not ask whether the support agent saw an asterisk on their screen. They ask whether the data was adequately protected throughout its lifecycle - at collection, in transit, at rest, in backups, in observability systems, and in every other place it came to exist.
DPDP compliance for SaaS organisations requires a comprehensive data flow map - one that documents every system where personal data exists, not just the primary data store. The backend exposure surfaces described in this post are almost always present in that map and almost always undocumented. Building the data flow map is the first step. Implementing vault-first tokenization at every surface is the second.
For fintech organisations additionally subject to RBI data localisation requirements, the on-premise deployment option for Securelytix ensures that tokenization infrastructure and vault operations run within Indian territory, satisfying data residency obligations while providing the full backend coverage that compliance requires.
Protection Has to Live Where the Data Lives
The deepest architectural principle in this space is the simplest: protection has to live where the data lives, not where the data is displayed. A display control protects a display. A data control protects data. These are not the same thing, and conflating them is how organisations end up with clean-looking dashboards and leaking backends.
Frontend masking is not wrong. It is appropriate. Support agents should see asterisks. Display layers should not render full Aadhaar numbers. These are correct user interface decisions. The mistake is treating them as data security decisions.
Data security decisions live in the backend - at the API boundary where data enters the system, in the event queue where it propagates, in the tracing infrastructure where it is observed, in the backup layer where it is preserved, and in the internal tools where it is accessed by the people who build and operate the system. Every one of these places requires its own protection, appropriate to the data that flows through it.
Vault-first architecture is the design philosophy that makes this manageable. Instead of implementing a different control at each of the eight backend surfaces, you implement one control - tokenization at the point of collection - and the consequence is that every downstream surface handles tokens rather than real values. The eight surfaces become eight places where tokens flow, rather than eight places where PII leaks.
That is a fundamentally different security posture. And it is one that frontend masking, however well-implemented, can never provide.
Frequently Asked Questions
We already mask PII in our API responses. Doesn't that handle the API layer exposure?
Masking in the API response addresses one direction - what the API returns to a caller. It does not address what was logged when the request arrived. The incoming request - the one containing the raw Aadhaar number submitted by the user - has already been received and potentially logged by the API gateway before any response masking takes effect. Vault-first tokenization at the collection boundary means the incoming request itself contains a token, so the API gateway's access log records a token from the first moment of contact.
How do we protect PII in Kafka without re-architecting our entire event pipeline?
The most practical approach is to intercept at the producer level. A thin SDK wrapper around your Kafka producer scans event payloads for fields matching your configured PII schema and tokenizes them before the message is published. Consumers downstream receive tokenized events without modification. For consumers that need real values - a KYC service performing a UIDAI check, for example - the vault SDK handles detokenization with purpose declaration and audit logging. The rest of the consumer ecosystem continues without changes.
Our staging environment uses production data for realistic testing. What is the right approach?
The right approach is synthetic data generation using format-preserving tokens. Securelytix can generate structurally valid, statistically realistic synthetic records in which all sensitive fields are format-preserving tokens with no real-value mappings. Your staging environment gets data that looks exactly like production - same Aadhaar format, same PAN format, same phone number format - and is safe to use without any access controls, because there are no real values in it to protect. This is the definitive answer to how to handle PII in test environments.
Can we scrub PII from distributed traces after the fact rather than intercepting before export?
Post-hoc scrubbing is unreliable for three reasons. First, traces are often indexed and searchable in the observability platform within seconds of export - scrubbing after the fact may be too late to prevent indexing of the raw value. Second, the scrubbing logic has to be comprehensive enough to catch PII in all its forms - structured fields, natural language text, embedded JSON in string attributes - which is a hard NLP problem, not a simple regex. Third, the real value has already left your infrastructure boundary by the time you are scrubbing. Interception before export is the only approach that reliably prevents transmission.
What is the difference between data masking, data tokenization, and data pseudonymisation under DPDP?
Under DPDP, masking - displaying partial values like XXXX XXXX 2345 - is a display control with no direct legal effect on obligations. Tokenization replaces a real value with a surrogate identifier managed by a vault; when done with a privacy vault under access controls and audit trails, it satisfies the pseudonymisation standard. Pseudonymisation under DPDP means that the data can no longer be attributed to a specific individual without access to separately held additional information - which is precisely what a vault provides. Tokenized data is pseudonymous; masked data is not, because the real value still exists in the same system.
How do we handle internal admin tools that currently display raw PII to the operations team?
There are two approaches depending on the tool's architecture. If the tool queries the database directly, the most robust fix is to ensure the database column it reads holds tokenized values, and to provide the tool with a detokenization integration scoped to the minimum required fields with purpose declaration and audit logging. If the tool calls an application API, a response transformation layer can tokenize or mask fields before they reach the tool's display layer. In either case, the goal is the same: the operations team sees what they need to do their job, but the data the tool handles and logs is tokens rather than real values.
Is vault-first architecture practical for organisations with large legacy backends?
Yes, through phased adoption. Securelytix supports a dual-read mode that allows tokenized new writes while existing read paths continue to function during migration. Most organisations begin with the highest-risk surfaces - the primary data ingestion API and the most sensitive fields - and expand coverage progressively. The migration typically follows the data flow: collection boundary first, then messaging layer, then observability. Each phase reduces exposure and creates audit coverage without requiring a flag-day cutover of the entire backend.
Ready to Secure Sensitive Data?
Explore how Securelytix helps teams protect sensitive data, enforce privacy controls, and build Secure AI deployment.