How Agentic AI Can Accidentally Leak PII Across Modern Backend Pipelines
Securelytix Team
Product & Security
20 May 2026
The New Attack Surface Nobody Drew on the Architecture Diagram
For years, the question of how to protect customer data in SaaS and enterprise systems has had a relatively stable answer: encrypt it at rest, tokenize the sensitive fields, control who can query the database, and audit the access logs. The perimeter was clear. The data lived in known places. The people and services that could touch it were enumerable.
Agentic AI broke that model quietly and comprehensively. Not through any dramatic security failure - but through the ordinary operation of systems that were never designed with PII propagation in mind. When you give an AI agent access to your customer records so it can answer support queries, process loan applications, or run KYC checks, you are not just giving it access to a database. You are creating a pipeline through which sensitive data - Aadhaar numbers, PAN cards, phone numbers, account balances - flows across boundaries that your existing data privacy controls were never built to govern.
The question of how to use LLMs without exposing PII is one of the most urgent and least solved problems in enterprise AI deployment today. Most teams discover they have a problem only after something has already gone wrong - when a compliance team finds raw Aadhaar numbers in their observability platform, or when a security review turns up PII in a vector database that was never supposed to hold it.
This post is an attempt to map that problem clearly - where the leaks actually happen in agentic AI pipelines, why they are architecturally different from the PII risks teams already know how to manage, and what a vault-first architecture looks like when it is applied to this new class of exposure.
What Makes Agentic AI Different from a Standard API Call
A conventional backend service has a relatively predictable data flow. A request comes in, a database query runs, a response goes out. The PII that moves through that flow is bounded - it enters at a known point, travels a defined path, and exits at a known point. Tokenizing sensitive fields at the API boundary and redacting PII from logs are well-understood problems with well-understood solutions.
An agentic AI system is different in three fundamental ways that make PII propagation much harder to control.
Agents Accumulate Context
A standard API call is stateless - each request is independent. An agent is stateful. It builds up a context window over the course of a session, accumulating information from user inputs, tool responses, memory retrievals, and prior reasoning steps. By the time an agent is three or four turns into a conversation about a loan application, its context window may contain the applicant's name, Aadhaar number, PAN, phone number, income details, and employment history - all simultaneously, all in plaintext, all available to whatever LLM is doing the reasoning.
What is sensitive data exposure in this context is not a breach of a perimeter. It is the ordinary operation of a feature that was designed to work this way. The agent is doing exactly what it was built to do - maintaining context. The problem is that the context is full of PII and nothing is managing where that context goes.
Tool Calls Pull Data Aggressively
Agents are designed to call tools - APIs, databases, search functions, external services. When an agent calls a CRM API to look up a customer record, it does not receive a carefully scoped response containing only the fields relevant to the current task. It receives the full record: every field that was stored, formatted in whatever structure the API returns. The agent then incorporates that entire response into its context window.
This is the what is sensitive data exposure problem at its most concrete. The agent asked a narrow question - "what is the loan status for this applicant" - and received a broad answer that includes every piece of PII ever collected on that person. None of the existing controls on the CRM API or the database were designed to scope responses to what an AI agent needs right now.
The Reasoning Step Itself Is a Transmission Event
When an agent sends its context window to an LLM for reasoning - whether that is an internally hosted model or an external provider like OpenAI, Anthropic, or Google - it is transmitting data. If that context window contains raw PII, the transmission contains raw PII. This is true regardless of whether TLS protects the transit. The data leaves your infrastructure boundary and enters the inference infrastructure of a third party.
For most organisations operating under DPDP, GDPR, or PCI-DSS, this transmission is either a compliance violation or operates in a legal grey area that would not survive regulatory scrutiny. And it happens silently, on every inference call, without any explicit decision by any engineer to share that data.
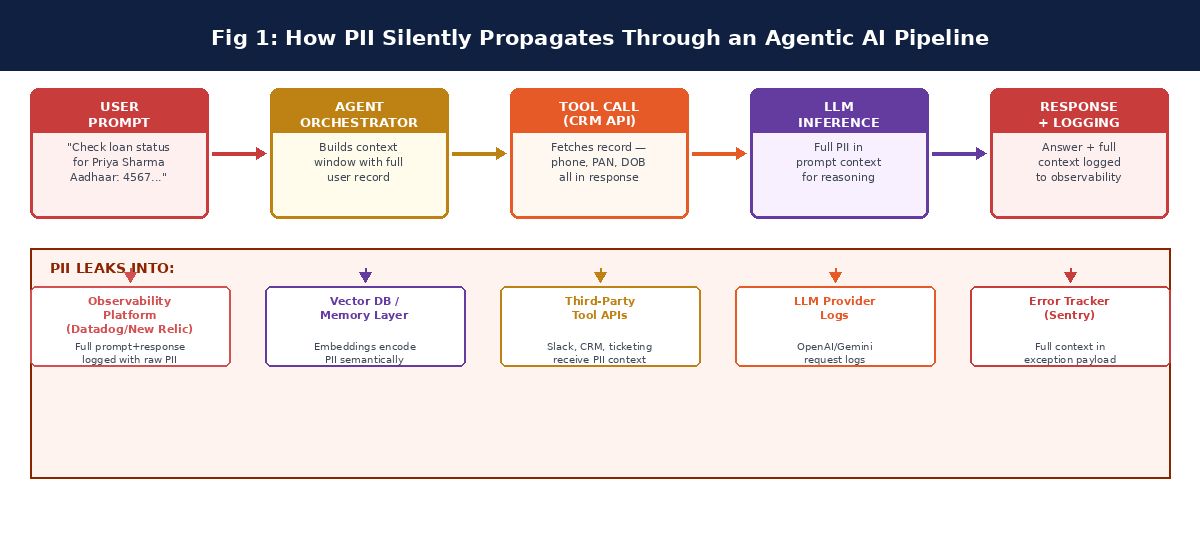
The Seven Places PII Leaks in an Agentic Pipeline
To design controls that actually work, you need to know where the data goes. In a typical agentic AI deployment, there are seven distinct surfaces where PII can escape into systems that were never intended to hold it.
1. The Prompt Itself
Users tell agents things. This is by design. A support agent needs to know who it is talking to. A KYC agent needs the applicant's details. A loan processing agent needs income and identity information. The problem is that this information arrives in the prompt context as raw text, and the agent framework treats it the same way it treats any other input - it logs it, traces it, and passes it forward without any awareness that some of the text is regulated personal data.
The prompt is the entry point for PII into the agentic pipeline. Everything that follows is a consequence of what entered here unprotected. This is why how to protect customer data in SaaS environments that use AI agents starts with the input layer - not the database layer.
2. Tool Call Responses
When an agent calls a tool - a database query, a CRM lookup, a payment API - the response comes back as a structured object and is injected directly into the agent's context. If the tool returns a full user record, that entire record becomes part of the context window. PAN numbers, Aadhaar numbers, account balances, medical information - all of it sits in the context window, available for subsequent reasoning steps and, more critically, for the observability and logging infrastructure that records what the agent was doing.
Most organisations that have invested in PII tokenization API for their backend databases have done so at the storage and retrieval layer - the database returns tokenized values. But agentic systems often call application-layer APIs rather than databases directly, and those APIs may return detokenized values as part of their normal response format.
3. The Memory and RAG Layer
Many agentic systems include a memory layer - a vector database like Pinecone, Weaviate, or pgvector that stores embeddings of past interactions so the agent can retrieve relevant context in future sessions. This is a genuine capability improvement. It is also a significant and underappreciated PII risk.
When an interaction that contains PII is embedded and stored in a vector database, the PII does not disappear into the embedding. Vector embeddings are not a form of anonymisation or de-identification. Research has repeatedly demonstrated that PII can be extracted from embeddings through inversion attacks. More practically, the raw text from which the embedding was generated is almost always stored alongside it - meaning that a vector database used for agent memory is, in effect, a database of raw PII from every customer interaction the agent has ever had.
This is what what is data de-identification looks like when applied incorrectly. Teams assume that because the data has been transformed into vectors, it is somehow protected. It is not.
4. Observability and Tracing Platforms
Modern agentic systems are instrumented heavily. Distributed tracing, span logging, LLM request/response logging, error capture - all of it is standard DevOps practice and genuinely necessary for operating these systems at production scale. The problem is that every one of these instrumentation points captures the data that was flowing through the system at that moment.
A trace of an agent handling a KYC query will contain the user's Aadhaar number in the input span, the full customer record in the tool call span, and the agent's reasoning about that data in the LLM span. That trace is shipped to Datadog, New Relic, Grafana, or whatever observability platform the team uses. That platform is a third-party SaaS vendor. The PII is now in a third-party system under terms of service that were almost certainly not reviewed through a DPDP data processor lens.
Knowing how to redact PII from logs before they leave your infrastructure boundary is one of the highest-priority DevSecOps data privacy best practices for any team running agentic AI in production.
5. The LLM Provider Boundary
Unless your organisation runs its own inference infrastructure - a significant undertaking - your agent is sending inference requests to an external LLM provider. That request contains the full context window. If the context window contains raw PII, the provider receives raw PII. Regardless of your data processing agreement with the provider, this is a transmission of personal data outside your infrastructure, and it triggers obligations under DPDP and GDPR.
This is the crux of how to give LLM access to customer records safely - the answer is that you do not give the LLM the real records. You give it tokenized records, and you detokenize only at the point where a real value is needed for an action that cannot be taken with the token alone.
6. Agent Handoffs and Sub-Agent Spawning
Complex agentic systems often involve multiple agents - an orchestrator that delegates to specialist sub-agents, or a chain of agents where one's output becomes another's input. Each handoff is a trust boundary crossing. When the orchestrator passes its accumulated context to a sub-agent, it is transmitting every piece of PII that was in that context - whether or not the sub-agent needs it for its specific task.
This is the agentic equivalent of the over-permissioning problem we covered in the PBAC blog. The sub-agent handling a credit score calculation does not need the applicant's Aadhaar number. But if the orchestrator's context contains it and is passed wholesale to the sub-agent, the sub-agent has it anyway.
7. Error Handling and Exception Capture
When an agentic system throws an exception - and they do, frequently, because they are complex systems with many failure points - the error handling infrastructure captures as much context as possible to aid debugging. In most implementations, this means the full context window at the time of the exception ends up in the exception payload, which is shipped to Sentry, Rollbar, or similar error tracking platforms.
A single unhandled exception during a KYC workflow can result in an Aadhaar number, PAN card, and phone number being transmitted to an external error tracking vendor in a single event. This is not a hypothetical. It is a routine occurrence in agentic systems that have not been designed with PII propagation in mind.
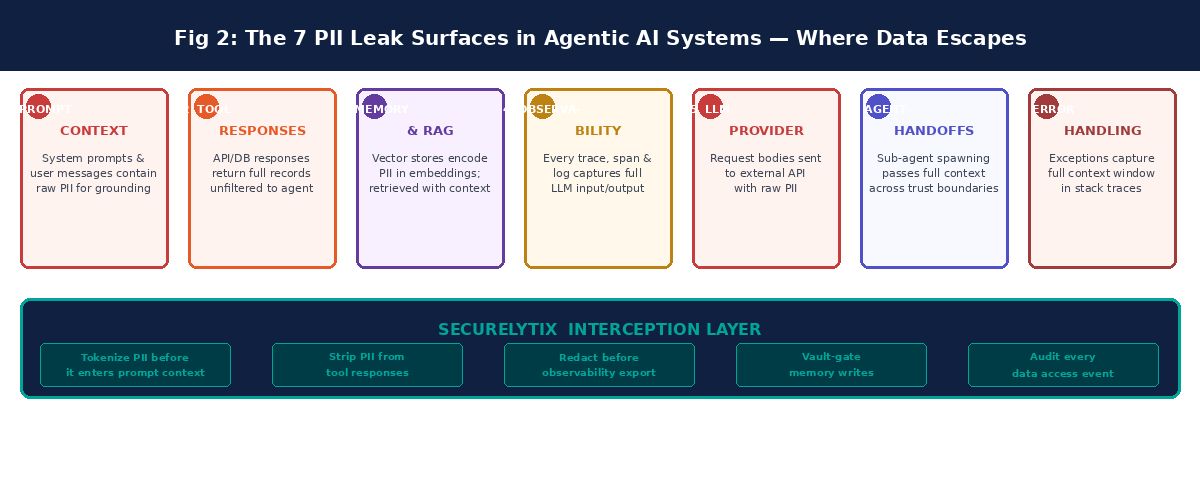
Why Existing Controls Don't Cover This
The natural response to each of the seven leak surfaces described above is to point to existing controls. We tokenize our database. We have log scrubbing rules. We reviewed our vendor DPAs. These are real controls and they are not worthless. But they were designed for a different threat model - one where data flow is predictable, bounded, and primarily horizontal (service to service at the application layer).
Agentic AI introduces vertical data propagation. PII doesn't just move between services - it moves up through abstraction layers into AI reasoning contexts and then back down into storage, logging, and observability systems. The controls that work for horizontal propagation - field-level tokenization, API gateway redaction, log scrubbing rules - don't intercept data at the points where vertical propagation happens.
THE CONTROL GAP
Your PII tokenization API protects data at the database layer. Your log scrubbing rules protect data in application logs. Neither of them operates at the context window boundary, the embedding write boundary, or the LLM inference boundary - which are the three most significant new PII leak surfaces that agentic AI introduces.
Building a zero trust data security posture for agentic AI means extending your existing controls to these new boundaries. It does not mean replacing what you already have.
There is also a data minimisation problem specific to agentic systems. The principle of data minimisation - collecting and processing only the data necessary for the specific purpose - is a foundational requirement of DPDP and GDPR. Agentic systems systematically violate it by design. They accumulate all available context because more context generally produces better results. The architecture is in direct tension with the regulatory requirement.
Resolving that tension requires architectural intervention - not at the level of the agent framework, but at the level of what data the agent is permitted to accumulate in the first place.
What a Vault-First Architecture Looks Like for Agentic AI
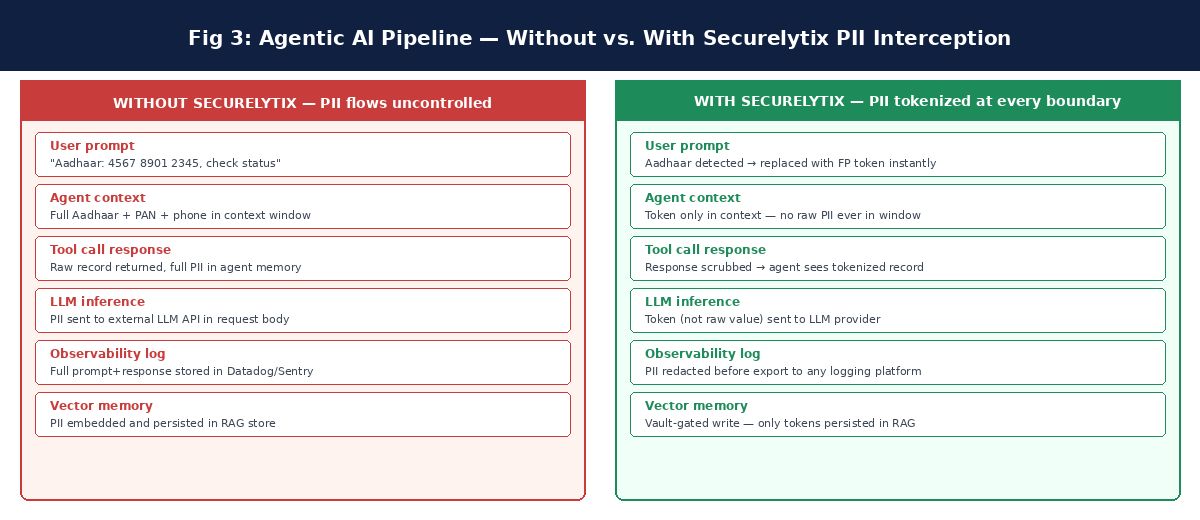
The vault-first architecture principle - protecting data at the point of collection rather than at the point of storage - applies to agentic AI pipelines with some important extensions. The core idea remains the same: sensitive data should be replaced with format-preserving tokens before it enters any system boundary that you do not fully control. The implementation has to account for the new boundaries that agentic systems create.
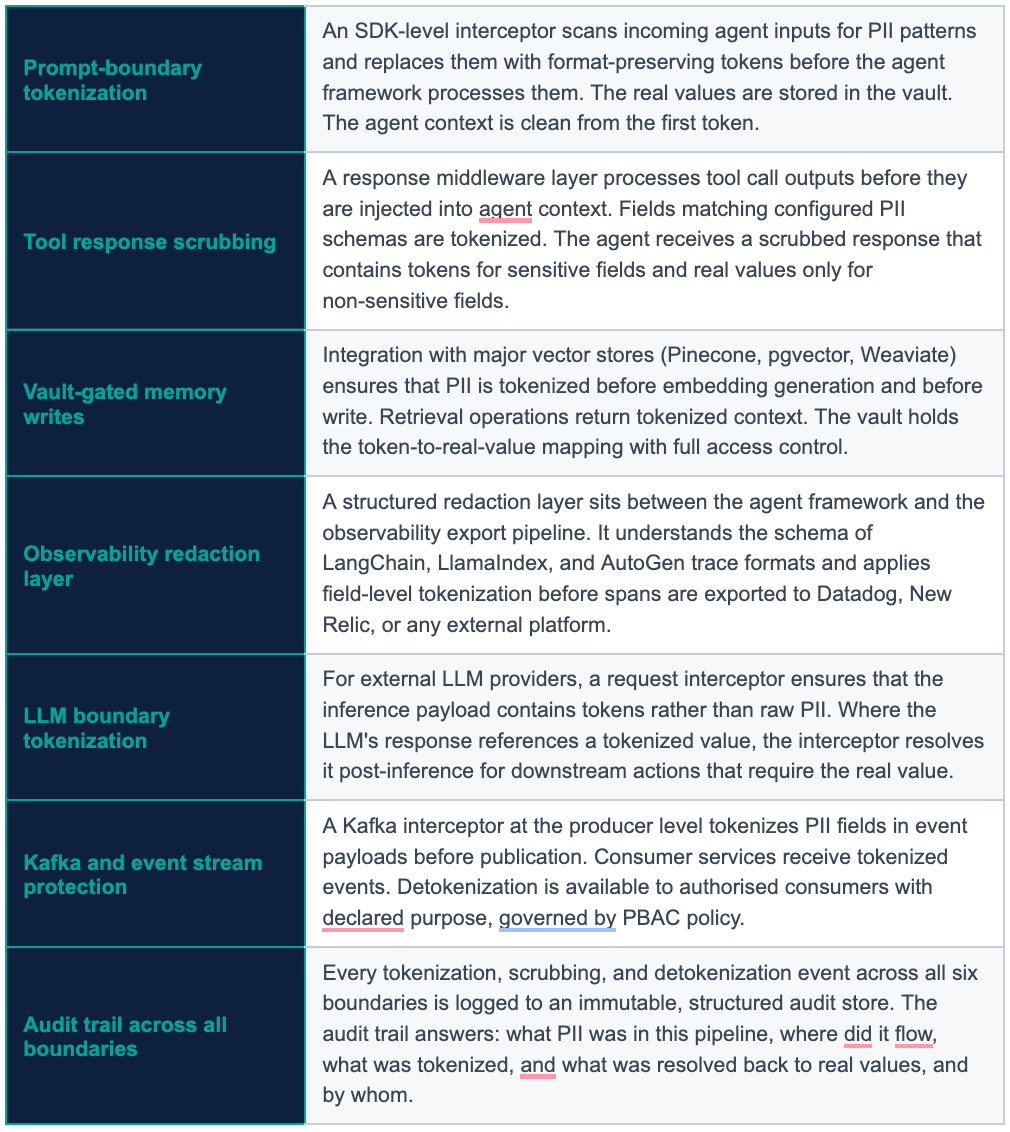
Tokenize at the Prompt Boundary
The first interception point is the incoming user message. Before the agent framework processes it, a PII detection and tokenization layer scans the input for sensitive fields - Aadhaar patterns, PAN formats, phone numbers, email addresses, card numbers - and replaces them with format-preserving tokens. The agent receives a prompt that contains tokens rather than real values. The real values are in the vault.
This single intervention prevents the raw PII from ever entering the context window. Everything that follows - the tool calls, the reasoning, the logging - operates on tokens rather than real values.

Scrub Tool Call Responses Before They Enter Context
The second interception point is the tool call response layer. When an agent calls a CRM API or a database and receives a full customer record, that response should be scrubbed before it is injected into the context window. Fields that the agent does not need for its current task should be stripped or tokenized. Fields that the agent does need but should not be transmitted raw to the LLM provider should be replaced with tokens.
This is where how to protect customer data in SaaS with agentic AI gets architecturally concrete. It is not enough to tokenize the database. You have to tokenize the response at the point where it enters the AI reasoning layer.
Vault-Gate Memory Writes
Before any interaction is embedded and written to the vector memory layer, it should pass through a tokenization gate. The raw text from which the embedding is generated should be tokenized, and the mapping between the token and the real value should live in the vault rather than in the vector database. Retrieval operations should return tokenized context that the agent can reason with, with detokenization available only for the specific fields that require it for specific actions.
This is the correct implementation of what is data pseudonymisation in the context of RAG and agent memory systems. The embeddings represent pseudonymised text. The real values are accessible only through a controlled, audited vault interface.
Redact Before Observability Export
Every trace, span, and log entry that contains agent context should be processed by a redaction layer before it is exported to any observability platform. This is a specific instance of the broader how to redact PII from logs problem, with the additional complexity that agent logs are semi-structured and the PII within them may appear in nested JSON, in natural language, or in structured tool call arguments.
The redaction layer needs to understand the data model of the agent framework being used - LangChain, LlamaIndex, AutoGen, or whatever orchestration layer is in play - and apply tokenization to the specific fields within that structure that may contain PII. Generic text scrubbing is not sufficient for agent logs.
Enforce Purpose Limitation on Detokenization
When a token does need to be resolved back to a real value - for a UIDAI verification call, a payment transaction, a regulatory reporting requirement - that detokenization should be subject to the same policy-based access control principles we covered in our previous post on PBAC. The agent, or the sub-agent, or the tool, must declare a business purpose. The vault validates that the declared purpose is permitted for the calling identity in the current context. The access is logged.
This is how you prevent the scenario where an agent accumulates tokens across a session and then bulk-resolves them through an API that was designed for a different purpose. Purpose limitation is enforced at the vault level, not at the application level.
The Kafka and Event Stream Problem
Many enterprise agentic systems are event-driven. Agent actions trigger events that are published to Kafka streams, consumed by downstream services, and persisted in event logs. This introduces another PII propagation surface that deserves specific attention.
If an agent publishes an event that contains customer context - as is common in loan processing, insurance claims, and KYC workflows - and that event contains raw PII, then every consumer of that Kafka topic receives raw PII. Every service that reads from the topic's retention window has access to raw PII. Every backup of the Kafka log contains raw PII.
How to protect PII in Kafka streams in an agentic context means ensuring that events published by agents contain tokens rather than real values. The same tokenization layer that intercepts the prompt boundary should intercept the event publication boundary. This is a specific application of the vault-first architecture principle to the event streaming layer.
What Securelytix Provides for Agentic AI Pipelines
Securelytix - India's first indigenous privacy vault - was built with the understanding that data privacy is not a backend-only problem. The agentic AI use case is one of the clearest demonstrations of why that is true. Here is how the platform addresses each of the leak surfaces described in this post:
The DPDP and Regulatory Dimension
India's Digital Personal Data Protection Act creates specific obligations that are directly triggered by agentic AI deployments. As a data fiduciary, an organisation deploying an AI agent that processes Aadhaar numbers or other personal data is required to implement appropriate technical measures to protect that data, to limit processing to the declared purpose, and to ensure that data is not transmitted to third parties without appropriate safeguards.
Sending raw Aadhaar numbers to an external LLM provider's inference endpoint as part of an agent context window is almost certainly a cross-border data transfer under DPDP - one that requires either explicit consent or a contractual arrangement that satisfies the Act's requirements for transfers to data processors. Most organisations that have deployed agentic AI have not evaluated whether their inference provider relationship satisfies these requirements, because they have not fully mapped where the PII in their agent pipelines goes.
The audit trail that a vault-first architecture produces is the foundation for that mapping. It is also the evidence that demonstrates, when a regulator asks, that the organisation took appropriate measures to protect personal data at every boundary in its AI pipeline - not just at the database layer.
For fintech organisations operating under both DPDP and RBI data localisation guidelines, the on-premise deployment option for Securelytix ensures that the vault infrastructure - and by extension the tokenization and detokenization operations - runs entirely within Indian territory, satisfying data residency requirements without constraining the AI capabilities the system is designed to enable.
Building AI Systems That Do Not Leak
The agentic AI PII problem is not a reason to avoid building agentic systems. The capability is too valuable and the competitive pressure is too strong. It is a reason to build them correctly - with the same architectural discipline that mature organisations apply to database security, API design, and access control.
The data minimisation principle applies to AI pipelines. The purpose limitation principle applies to detokenization. The vault-first architecture principle applies to every boundary where PII crosses from your controlled infrastructure into an AI reasoning layer, an external provider, or an observability platform.
None of this is technically exotic. The primitives are the same ones that protect PII in any other part of a modern backend: tokenization, access control, audit trails, and policy enforcement. What is new is the set of boundaries where those primitives need to be applied. The context window boundary. The embedding write boundary. The observability export boundary. The LLM inference boundary.
These boundaries did not exist five years ago. The tools to protect them are available now. The organisations that build AI systems with vault-first thinking from the start will not have to retrofit privacy architecture onto a pipeline that has been leaking silently for two years. They will also be the ones that can demonstrate DPDP compliance when the regulator asks - not because they wrote a policy, but because they built an architecture.
That is the difference Securelytix is designed to make.
Frequently Asked Questions
How is the agentic AI PII problem different from the standard API logging PII problem?
The standard API logging problem is bounded: PII enters an endpoint, a log line captures it, you scrub the log. The agentic AI problem is unbounded in two ways. First, the accumulation problem: an agent builds up a context window across multiple turns and tool calls, so the PII concentration in a single context window can be much higher than in a single API request. Second, the vertical propagation problem: the context window flows up into AI reasoning infrastructure and down into observability, memory, and error handling systems - crossing many more boundaries than a standard API call does.
Are vector embeddings a safe way to store PII? Can they be treated as anonymised data?
No. Vector embeddings are not a form of anonymisation or de-identification under DPDP or GDPR. The raw text from which embeddings are generated is almost always stored alongside them. And research has demonstrated that PII can be extracted from embeddings through model inversion attacks. A vector database used for agent memory should be treated as a PII store and governed accordingly - with tokenization of sensitive fields before embedding generation, access controls on the raw text store, and audit trails on retrieval.
What is the right way to give an AI agent access to customer records without exposing raw PII?
The pattern is: tokenize the record before it enters the agent's context, allow the agent to reason with tokens throughout, and detokenize only at the specific point where a real value is needed for an action that cannot be taken with the token alone. For example, an agent can retrieve a customer's loan application, reason about it, draft a response, and escalate an issue - all using tokenized field values. Only when the agent needs to make a UIDAI verification call or a payment disbursement does it need the real value, and that detokenization is purpose-bound, scoped, and audited.
How do you redact PII from observability platforms like Datadog or New Relic when the data is in LLM traces?
The interception has to happen before the data leaves your infrastructure - not at the observability platform level. A structured redaction layer sits between your agent framework's tracing instrumentation and the export pipeline. It understands the trace schema of your agent framework (LangChain, LlamaIndex, etc.) and applies field-level tokenization to inputs, outputs, and tool call arguments before the span is shipped. Generic regex-based scrubbing is not sufficient because LLM contexts contain PII in unstructured natural language as well as structured fields. A schema-aware tokenization layer is required.
Does running an on-premise LLM solve the PII propagation problem?
It solves the external transmission problem - if you run your own inference infrastructure, the context window does not leave your boundary. But it does not solve the observability problem, the memory layer problem, the tool call response problem, or the agent handoff problem. On-premise inference is one input to a defence-in-depth posture, but it is not a substitute for vault-first tokenization at the context window boundary. Teams that adopt on-premise LLMs and assume that solves their AI PII risk typically still have raw PII flowing through their agent contexts, memory systems, and logs.
How does Securelytix integrate with existing agent frameworks like LangChain or LlamaIndex?
Securelytix provides SDK-level interceptors for the major Python and JavaScript agent frameworks. The interceptors hook into the framework's input processing, tool call response handling, and observability export pipelines. Integration is typically a few lines of configuration at the agent initialisation level rather than a per-tool or per-endpoint modification. The vault and policy engine run as a sidecar service in your infrastructure, so tokenization and detokenization latency is sub-5ms for the token resolution path.
Is this a DPDP compliance requirement or a best practice?
Both. Under DPDP, organisations that process personal data are required to implement appropriate technical measures proportionate to the risk. Sending raw Aadhaar numbers to an external LLM inference endpoint almost certainly constitutes a cross-border data transfer requiring safeguards under the Act. That is a compliance requirement. Beyond the letter of the regulation, vault-first tokenization for agentic AI is also the correct engineering posture - it reduces your blast radius in the event of a breach, limits the scope of any future regulatory investigation, and allows you to demonstrate that you took the data protection obligation seriously from the architectural level. That demonstration is increasingly what regulators are looking for.
Ready to Secure Sensitive Data?
Explore how Securelytix helps teams protect sensitive data, enforce privacy controls, and build Secure AI deployment.